在當今數字化的時代,大數據已成為驅動社會進步和科技創新的核心要素。無論是智能推薦、醫療診斷,還是城市規劃、氣候預測,背后都離不開海量數據的支撐。這些用于處理和分析的龐大數據究竟從何而來?它們又是如何被收集、存儲并最終轉化為有價值的信息的?本文將深入淺出地探討大數據處理的源頭及其與數據處理、存儲的緊密關系。
一、大數據的主要來源
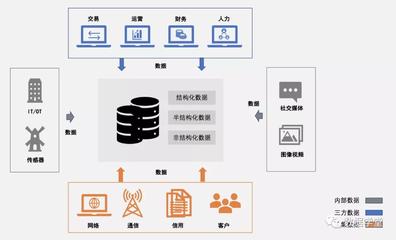
大數據的來源極為廣泛,幾乎涵蓋了人類活動和自然世界的各個方面。可以歸納為以下幾個主要渠道:
- 互聯網與社交媒體:這是數據量最大、增長最快的來源之一。包括:
- 用戶生成內容(UGC):我們在社交媒體(如微博、微信、抖音)上發布的文字、圖片、視頻、點贊、評論和轉發。
- 網絡行為數據:在搜索引擎的查詢記錄、電商平臺的瀏覽與購買歷史、新聞APP的點擊流、視頻網站的觀看記錄等。
- 服務日志:各類網站、應用程序、服務器在運行過程中自動產生的日志文件,記錄了每一次訪問的詳細信息。
- 物聯網(IoT):隨著傳感器和智能設備的普及,物理世界正在被全面數字化。數據來源包括:
- 智能硬件:智能手機的GPS位置、運動傳感器數據;智能手環/手表采集的心率、睡眠、步數等健康數據。
- 工業物聯網:生產線上的傳感器實時監測設備狀態、溫度、壓力、振動;智能電表、水表記錄資源消耗。
- 智慧城市:交通攝像頭、環境監測站、智能路燈等公共設施產生的視頻流和環境數據。
- 傳統企業與組織機構:這是歷史悠久且結構化的數據來源。
- 業務交易數據:銀行、保險、零售業的交易記錄、財務報表、客戶信息等。
- 醫療健康數據:醫院的電子病歷、醫學影像(CT、MRI)、基因組學數據、可穿戴設備上傳的健康信息。
- 科研數據:大型科學實驗(如粒子對撞機、天文望遠鏡)、氣候模擬、生物信息學研究產生的超大規模數據集。
- 公共與開放數據:由政府、研究機構等公開提供的數據集,用于促進透明度和創新。
- 政府公開數據:人口普查數據、經濟統計數據、地理信息系統(GIS)數據、氣象數據等。
- 開源數據集:學術界和科技公司為促進研究而公開的數據集,如ImageNet(圖像識別)、Common Crawl(網頁抓取數據)等。
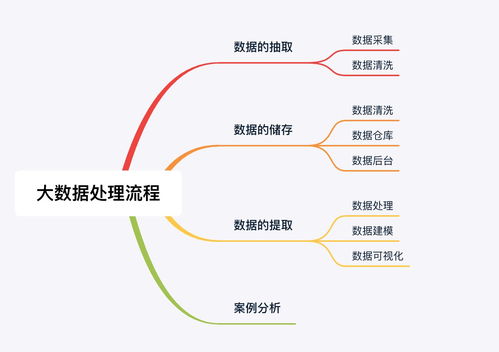
二、從數據源頭到處理與存儲的流程
原始數據如同未經提煉的礦石,需要經過一系列環節才能變成有價值的“信息金礦”。這個過程主要包含采集、存儲、處理和分析幾個關鍵階段。
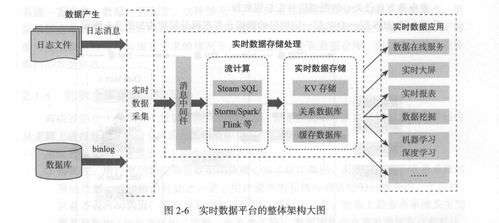
- 數據采集與攝取:
- 這是第一步,目標是將數據從源頭“搬”到數據系統中。技術手段多樣,包括:
- 網絡爬蟲:從互聯網上自動抓取網頁內容。
- 傳感器數據流:通過消息隊列(如Kafka)實時接收物聯網設備上傳的數據流。
- 日志收集器(如Flume, Logstash):集中采集分布在各服務器上的日志文件。
- 數據庫同步:將傳統業務數據庫的數據導出或實時同步到大數據平臺。
- 數據存儲:
- 海量、多樣、高速增長的數據對存儲提出了巨大挑戰。大數據存儲的核心思想是分布式存儲,即使用成百上千臺普通服務器組成集群來共同保存數據。主流技術包括:
- 分布式文件系統:如Hadoop HDFS,適合存儲超大文件,并提供高容錯性。
- NoSQL數據庫:如HBase、Cassandra、MongoDB,它們放棄了傳統關系型數據庫嚴格的一致性要求,以換取更好的可擴展性和靈活性,擅長處理半結構化和非結構化數據。
- 云對象存儲:如Amazon S3、阿里云OSS,提供了幾乎無限的存儲空間,通過簡單的API進行訪問,成本低廉,是存儲海量冷數據(不常訪問)的理想選擇。
- 存儲時,還需考慮數據的分層(熱數據、溫數據、冷數據),以優化成本和訪問效率。
- 數據處理與分析:
- 這是大數據的“煉金”階段,目標是從存儲的數據中提取洞見、發現規律、預測趨勢。處理模式主要分為兩類:
- 批處理:對一段時間內積累的大量數據進行離線計算,速度較慢但吞吐量大、分析深入。代表框架是Hadoop MapReduce及其之上的Hive、Spark等。常用于歷史數據分析、報表生成。
- 流處理:對連續不斷產生的數據流進行實時或近實時的計算,延遲極低。代表框架是Apache Flink、Spark Streaming、Storm。常用于實時監控、欺詐檢測、實時推薦等場景。
- 數據在分析前通常需要經過數據清洗、集成、轉換等預處理步驟,以確保數據質量。
三、一個生生不息的循環
大數據的生態系統是一個動態、閉環的循環:
數據來源(源頭) → 采集與攝取(搬運) → 分布式存儲(倉庫) → 處理與分析(煉金廠) → 產生洞見與價值(產品) → 指導行動/產生新數據(新源頭)
例如,一個電商平臺的推薦系統,其數據來源于用戶的點擊和購買行為(源頭),這些行為被實時采集并存儲于大數據平臺(存儲),通過流處理和機器學習模型進行分析(處理),實時生成個性化推薦列表(價值),用戶看到推薦后再次點擊或購買,又產生了新的數據,如此循環往復,不斷優化。
因此,理解大數據從何而來,是理解其整個處理與存儲邏輯的基石。正是這些來自四面八方、看似雜亂無章的原始數據,經過現代計算技術的精心梳理和提煉,最終匯聚成驅動智能時代的強大動力。