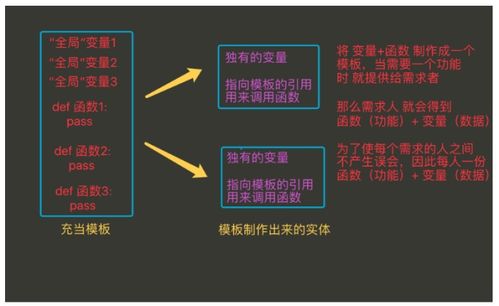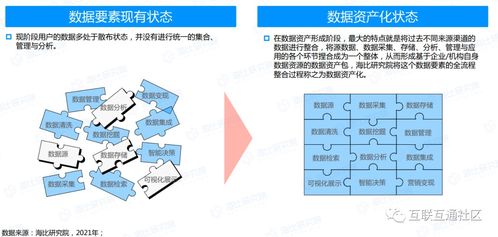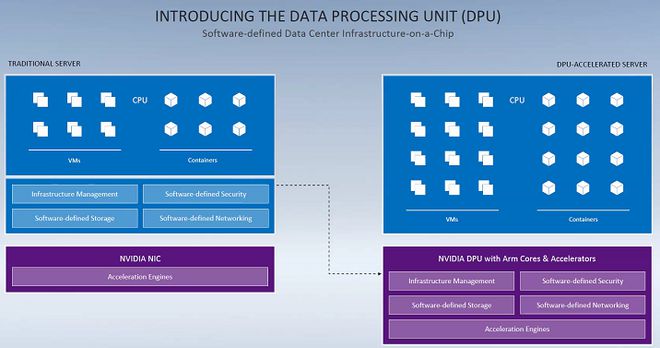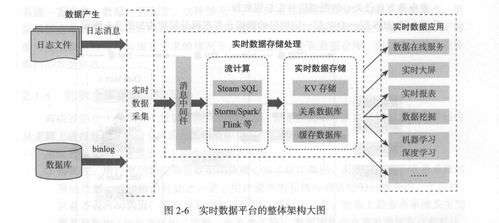
在閱讀《離線和實時大數據開發實戰》一書的過程中,我對其關于數據處理與存儲的論述有了較為深刻的理解。該書系統性地闡述了在大數據場景下,如何高效、可靠地處理與存儲海量數據,這不僅是技術挑戰,更是架構設計的藝術。
一、數據處理的雙軌制:離線與實時
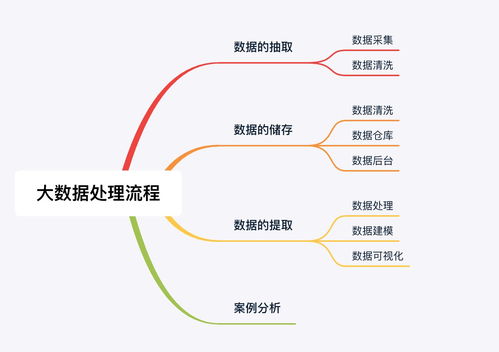
書中明確指出,現代大數據處理已形成離線和實時兩大并行體系。離線處理(如基于Hadoop MapReduce、Hive的批處理)適用于對時效性要求不高、但需復雜計算與全量分析的業務場景,其核心在于吞吐量與成本優化。而實時處理(如基于Apache Flink、Apache Storm的流計算)則應對瞬息萬變的業務需求,如實時監控、風險預警,其靈魂是低延遲與高可用。兩者并非替代關系,而是互補共存,共同構成企業數據驅動的雙引擎。書中通過實際案例,詳細對比了兩種模式在架構設計、資源調度、容錯機制上的異同,令人印象深刻。
二、數據存儲的分層與選型
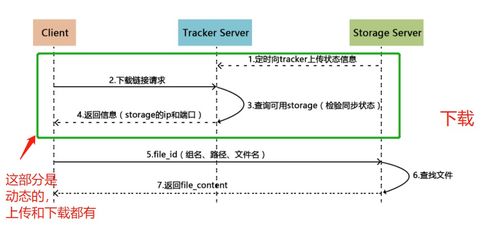
在存儲層面,本書強調了根據數據熱度、訪問模式、一致性要求進行分層存儲的重要性。從高速緩存(如Redis)、分布式文件系統(如HDFS)、NoSQL數據庫(如HBase、Cassandra)到數據倉庫(如Hive、ClickHouse),每一種存儲介質都有其特定的適用場景。書中特別指出,數據湖與數據倉庫的融合趨勢日益明顯,原始數據的低成本存儲與結構化數據的高效查詢需在架構上得到平衡。對于實時數據流,消息隊列(如Kafka)不僅作為數據傳輸的管道,其持久化機制也成為了流處理存儲設計的關鍵一環。
三、實戰中的挑戰與應對
理論終需落地。書中用了大量篇幅探討實戰中常見的問題:如何保證數據在離線和實時鏈路中的一致性(Lambda架構與Kappa架構的抉擇)?如何設計可擴展的存儲 schema 以應對業務快速變化?如何優化數據傾斜帶來的處理瓶頸?作者結合自身經驗,給出了具體的調優策略、監控指標與故障排查思路,極具參考價值。例如,通過壓縮算法、列式存儲提升I/O效率;通過窗口函數、狀態管理優化流處理邏輯;通過元數據管理、數據血緣保障數據質量與治理。
四、未來展望
隨著云原生、存算分離、湖倉一體等概念的興起,數據處理與存儲的邊界正在變得模糊,技術棧也在不斷演進。本書在最后也前瞻性地指出,未來的系統將更加強調彈性伸縮、自動化運維與智能優化。作為開發者,我們不僅要掌握當前主流框架,更需理解其背后的設計哲學,方能以不變應萬變。
這本《離線和實時大數據開發實戰》為我系統化理解大數據核心環節——數據處理與存儲提供了清晰的藍圖。它不僅是工具手冊,更是架構思想指南,提醒我們在紛繁的技術選型中,始終要回歸業務本質:數據如何高效、準確地轉化為價值。