在云計算與數據驅動時代,數據庫作為核心基礎設施,其性能、彈性與成本直接關系到企業的競爭力。阿里云自主研發的云原生關系型數據庫PolarDB,正是應對這一挑戰的杰出答案。它并非傳統架構的簡單上云,而是從設計之初就為云環境量身打造,尤其在數據處理與存儲層面實現了革命性突破。本文將深入剖析PolarDB在這一核心領域的創新架構與技術優勢。
一、 架構基石:計算與存儲分離
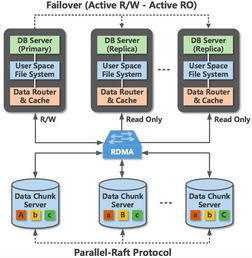
PolarDB最根本的創新在于其采用的 “計算與存儲分離” 架構。這與傳統數據庫(包括早期云數據庫)將計算節點與存儲緊密耦合的設計截然不同。
- 傳統瓶頸:在耦合架構中,計算能力的擴展(Scale-Up)受限于單臺服務器的硬件極限,而存儲容量與I/O性能的擴展同樣困難,且存在主備副本間數據同步延遲高、存儲成本成倍增加等問題。
- PolarDB的解決方案:PolarDB將計算節點(負責SQL解析、事務處理、緩存等)與分布式存儲集群(負責數據持久化)徹底解耦。計算節點是無狀態的,可以通過增加只讀節點實現近乎線性的讀擴展。存儲層則是一個共享的統一存儲池,所有計算節點(一個主節點和多個只讀節點)都訪問同一份數據,確保了數據的強一致性,避免了傳統主從架構中復制延遲帶來的讀寫不一致問題。
二、 存儲引擎的核心:PolarStore
存儲層的卓越性能是PolarDB的制勝關鍵,其核心是自研的分布式塊存儲系統——PolarStore。
- 高性能并行文件系統(PFS):PolarStore通過定制的用戶態文件系統PFS,繞過了操作系統內核的I/O棧,直接與存儲設備交互,大幅降低了I/O延遲。它對分布式SSD進行了深度優化,能夠實現高達百萬級的IOPS和極低的訪問延遲,滿足高并發在線事務處理(OLTP)場景的苛刻需求。
2. 數據一致性協議:Parallel Raft
為了在分布式存儲中保證數據的強一致性與高可用,PolarDB創新性地采用了 Parallel Raft協議。它是經典Raft共識算法的增強版。傳統Raft協議中,日志必須在組內順序復制,限制了吞吐。Parallel Raft則允許并行復制數據日志,只要日志之間沒有依賴沖突,就可以并發提交,極大地提升了存儲集群的寫入吞吐量,使整體性能不再受限于單個節點的I/O上限。
3. 智能分層與壓縮
PolarStore支持智能冷熱數據分層。頻繁訪問的“熱數據”存放在高性能SSD上,而較少訪問的“冷數據”會自動遷移至成本更低的存儲介質(如ESSD云盤)。結合高效的數據壓縮算法,在保證性能的前提下,可有效降低高達70%的存儲成本。
三、 數據處理能力的飛躍
基于上述存儲優勢,PolarDB在數據處理能力上實現了全面飛躍。
1. 極致彈性與快速擴展
由于計算與存儲分離,兩者可以獨立彈性伸縮。存儲容量按需自動擴展,最高可達100TB,且無需中斷業務。計算節點(特別是只讀節點)可以在分鐘級甚至秒級完成擴容或縮容,輕松應對電商大促、流量洪峰等突發場景。
2. 讀寫分離與全局一致性
多個只讀節點可以透明地分擔主節點的讀請求壓力。PolarDB通過全局時間戳(Global Timestamp Service) 和回放日志到內存的機制,確保了只讀節點能夠提供毫秒級延遲的強一致性讀,而不僅僅是最終一致性。這意味著應用程序無需修改代碼,即可讓讀請求訪問到剛寫入的最新數據,極大簡化了開發復雜度。
3. 軟硬協同優化
PolarDB深度利用RDMA(遠程直接內存訪問)網絡技術。在計算節點與存儲節點之間、以及存儲節點內部,通過RDMA進行高速數據傳輸,避免了內核協議棧處理和網絡延遲,實現了類似訪問本地SSD的極致I/O體驗。
4. 100%兼容性與生態無縫對接
PolarDB完全兼容MySQL、PostgreSQL和Oracle語法與協議。企業現有的應用系統可以幾乎零修改地遷移至PolarDB,并繼續使用豐富的周邊生態工具(如數據遷移、備份、BI分析工具),保護了現有投資,降低了遷移門檻和風險。
四、 與展望
阿里云PolarDB通過計算存儲分離架構、自研高性能分布式存儲PolarStore、創新的Parallel Raft協議以及軟硬一體的深度優化,重新定義了云原生關系型數據庫的標準。它完美地平衡了高性能、高彈性、高可用與低成本的“不可能三角”,為企業的核心業務系統提供了面向未來的數據基座。
隨著AI負載的興起,PolarDB正在向HTAP(混合事務/分析處理) 和AI for DB方向演進,旨在在一個數據庫內同時高效處理實時事務與即時分析,并利用機器學習實現智能調優、異常預測與自愈。阿里云PolarDB的持續創新,正引領著關系型數據庫進入一個全新的云原生智能時代。