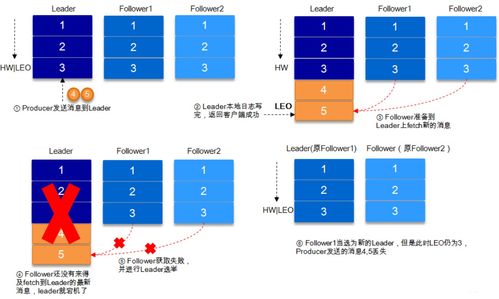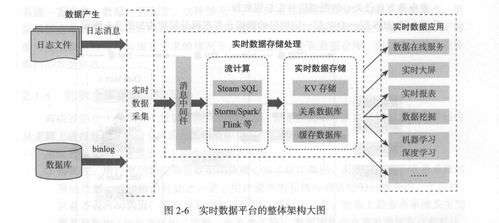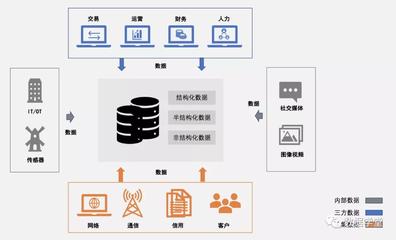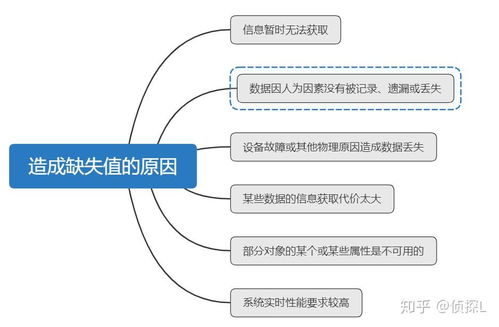
引言:Scala在大數(shù)據(jù)時代的角色
Scala作為一門運行在JVM上的多范式編程語言,憑借其強大的函數(shù)式編程能力、簡潔的語法以及對并發(fā)編程的天然支持,已成為大數(shù)據(jù)處理領(lǐng)域的重要工具。它與Apache Spark的深度集成,使得Scala成為大規(guī)模數(shù)據(jù)處理與存儲任務(wù)的首選語言之一。本指南旨在為開發(fā)者提供Scala在數(shù)據(jù)處理與存儲方面的核心知識與實踐技巧。
一、Scala數(shù)據(jù)處理基礎(chǔ)
1.1 核心數(shù)據(jù)結(jié)構(gòu)
Scala提供了豐富且靈活的數(shù)據(jù)結(jié)構(gòu),它們是構(gòu)建數(shù)據(jù)處理邏輯的基石。
- 集合框架:
List、Seq、Array、Set、Map等,支持不可變與可變版本,為數(shù)據(jù)處理提供了高性能的基礎(chǔ)容器。 - 高階函數(shù)與集合操作:
map、filter、flatMap、reduce、fold等函數(shù)是函數(shù)式數(shù)據(jù)轉(zhuǎn)換的核心。它們鼓勵聲明式編程,使代碼更簡潔、易讀且易于并行化。
val data = List(1, 2, 3, 4, 5)
val doubled = data.map(_ * 2) // 轉(zhuǎn)換:List(2, 4, 6, 8, 10)
val evens = data.filter(_ % 2 == 0) // 過濾:List(2, 4)
val sum = data.reduce( + ) // 聚合:151.2 模式匹配
模式匹配是Scala的“殺手級”特性,能夠優(yōu)雅地解構(gòu)和匹配復(fù)雜數(shù)據(jù)結(jié)構(gòu),極大地簡化了數(shù)據(jù)清洗、分類和路由邏輯。
def processRecord(record: Any): String = record match {
case (id: Int, name: String) => s"ID: $id, Name: $name"
case list: List[_] => s"List with ${list.size} elements"
case _ => "Unknown format"
}1.3 隱式轉(zhuǎn)換與類型類
通過隱式轉(zhuǎn)換和類型類,可以優(yōu)雅地為現(xiàn)有類型擴(kuò)展數(shù)據(jù)處理能力,例如為自定義數(shù)據(jù)類型自動添加序列化、排序或聚合方法。
二、與Apache Spark集成進(jìn)行大規(guī)模數(shù)據(jù)處理
Apache Spark是分布式數(shù)據(jù)處理的行業(yè)標(biāo)準(zhǔn),其核心API正是用Scala編寫的。
2.1 Spark核心概念
- RDD (彈性分布式數(shù)據(jù)集):Spark的底層抽象,代表一個不可變、可分區(qū)的數(shù)據(jù)集合。Scala的函數(shù)式風(fēng)格與RDD的轉(zhuǎn)換操作(如
map,filter)完美契合。 - DataFrame/Dataset:基于RDD構(gòu)建的更高級別的抽象,提供了結(jié)構(gòu)化數(shù)據(jù)的操作接口和Catalyst查詢優(yōu)化器。Dataset結(jié)合了RDD的類型安全與DataFrame的執(zhí)行效率。
2.2 使用Scala編寫Spark任務(wù)
`scala
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("ScalaDataProcessing").getOrCreate()
import spark.implicits._
// 讀取數(shù)據(jù)
val df = spark.read.option("header", "true").csv("path/to/data.csv")
// 使用Scala進(jìn)行數(shù)據(jù)轉(zhuǎn)換與聚合
val result = df
.filter($"age" > 18) // 過濾
.groupBy($"department") // 分組
.agg(avg($"salary").as("avgsalary")) // 聚合
.orderBy($"avgsalary".desc) // 排序
// 寫入存儲
result.write.parquet("path/to/output.parquet")`
2.3 性能優(yōu)化
- 合理分區(qū):使用
repartition或coalesce優(yōu)化數(shù)據(jù)分布。 - 廣播變量與累加器:利用
broadcast變量高效分發(fā)大只讀數(shù)據(jù),使用累加器進(jìn)行安全的全局聚合。 - 持久化策略:明智地使用
cache()或persist(),避免重復(fù)計算。
三、數(shù)據(jù)存儲與交互
數(shù)據(jù)處理的結(jié)果最終需要持久化,Scala生態(tài)系統(tǒng)提供了多種方式與存儲系統(tǒng)交互。
3.1 文件系統(tǒng)
- 本地/分布式文件系統(tǒng):通過Spark API或標(biāo)準(zhǔn)Java/Scala IO庫讀寫文本、CSV、JSON、Parquet、ORC等格式。Parquet因其列式存儲和高效壓縮,在大數(shù)據(jù)場景中尤為常用。
3.2 數(shù)據(jù)庫
- 關(guān)系型數(shù)據(jù)庫:使用JDBC通過Spark或獨立的庫(如Slick)進(jìn)行連接和操作。
- NoSQL數(shù)據(jù)庫:
- Cassandra:通過
spark-cassandra-connector庫無縫集成,支持將DataFrame直接讀寫到Cassandra表。
- HBase:通過
Hadoop Input/OutputFormat或Apache HBase的Spark Connector進(jìn)行操作。
- MongoDB:使用官方的MongoDB Spark Connector。
3.3 序列化與反序列化
高效的數(shù)據(jù)存儲離不開序列化。除了Java序列化,Scala社區(qū)推薦:
- Kryo:速度快、序列化結(jié)果體積小,是Spark中默認(rèn)推薦的序列化器(需注冊自定義類)。
- Avro/Protobuf/Thrift:這些跨語言、帶Schema的二進(jìn)制格式,非常適合長期存儲和跨系統(tǒng)數(shù)據(jù)交換。Scala有相應(yīng)的開源庫支持(如
avro4s,scalapb)。
四、最佳實踐與架構(gòu)建議
- 不變性與純函數(shù):盡可能使用不可變集合和純函數(shù),這能減少副作用,使代碼更易于測試、推理和在分布式環(huán)境中運行。
- 錯誤處理:善用
Option、Try、Either等Monadic類型來處理可能缺失或異常的數(shù)據(jù),避免使用null。 - 資源管理:使用
Loan Pattern或Scala ARM(自動資源管理,如Using對象)確保文件句柄、數(shù)據(jù)庫連接等資源被正確關(guān)閉。 - 模塊化與組合:將復(fù)雜的數(shù)據(jù)管道拆分為小的、可組合的函數(shù),利用Scala的面向?qū)ο蠛秃瘮?shù)式特性構(gòu)建清晰、可維護(hù)的架構(gòu)。
- 測試:使用ScalaTest或Specs2為數(shù)據(jù)處理邏輯(特別是純函數(shù)部分)編寫單元測試,確保其正確性。
###
Scala憑借其強大的語言特性和與Spark等大數(shù)據(jù)框架的深度集成,為構(gòu)建高效、可靠、易維護(hù)的大規(guī)模數(shù)據(jù)處理與存儲系統(tǒng)提供了卓越的工具集。掌握Scala的函數(shù)式編程范式、集合操作以及與各種存儲系統(tǒng)的交互方式,是成為一名高效大數(shù)據(jù)工程師的關(guān)鍵。隨著項目復(fù)雜度的提升,Scala在類型安全、表達(dá)能力和并發(fā)模型方面的優(yōu)勢將愈發(fā)明顯,助力應(yīng)對日益增長的數(shù)據(jù)挑戰(zhàn)。