隨著人工智能技術的飛速發展,大型語言模型(LLM)已成為推動行業創新的核心引擎。支撐這些龐然大物高效運行的背后,是日益復雜和挑戰性的數據存儲與管理需求。本文將深入探討在大模型實踐中,如何協同優化存儲性能、控制成本,并駕馭多云環境下的數據處理與存儲策略。
一、性能:為模型訓練與推理提供高速通道
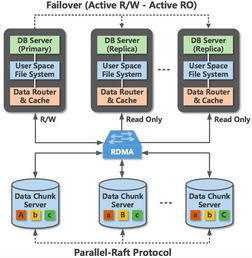
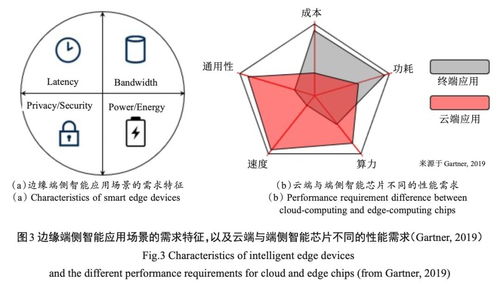
大模型的訓練涉及海量參數的反復讀寫與更新,對存儲系統的吞吐量、IOPS(每秒輸入/輸出操作次數)和延遲提出了極致要求。高性能存儲解決方案,如全閃存陣列、分布式存儲系統以及高性能并行文件系統(如Lustre, GPFS),已成為支撐千億乃至萬億參數模型訓練的基石。它們能夠確保數據管道永不成為瓶頸,讓寶貴的計算資源(如GPU集群)時刻處于飽和工作狀態。在推理階段,低延遲存儲則直接關系到終端用戶的體驗,需要針對模型加載、緩存和實時數據訪問進行專門優化。
二、成本:在資源需求與預算間尋找最優解
追求極致性能的成本控制是無法回避的現實。大模型存儲的成本構成復雜,包括硬件采購、軟件許可、機房空間、電力消耗、運維人力及云服務費用等。實踐中常采用分層存儲策略:將熱數據(如正在訓練的數據集、檢查點)存放于高性能層,而將溫冷數據(如歷史訓練日志、歸檔模型)遷移至成本更低的對象存儲或磁帶庫。數據去重、壓縮技術能有效降低存儲空間占用。利用云原生的彈性與按需付費特性,在訓練高峰期快速擴展高性能存儲,在空閑期縮減資源,是實現成本效益最大化的重要途徑。
三、多云數據處理與存儲:構建靈活穩健的架構
單一云或數據中心已難以滿足全球化、高可用的需求,多云策略成為主流。這為數據存儲帶來了新的維度:
- 數據編排與同步: 需要工具與策略來管理跨云的數據流動,確保訓練數據的一致性,并高效地將模型部署到不同區域的推理端點。
- 存儲抽象與可移植性: 通過Kubernetes CSI(容器存儲接口)或存儲抽象層,實現應用與底層云存儲服務的解耦,避免供應商鎖定,提升架構靈活性。
- 合規與數據治理: 不同地區的數據駐留(Data Residency)法規要求數據存儲在特定地域。多云存儲架構需內置策略引擎,自動滿足合規要求。
- 災備與業務連續性: 將關鍵模型和數據跨云備份與復制,是防范區域性服務中斷、保障業務連續性的關鍵。
實踐建議與未來展望
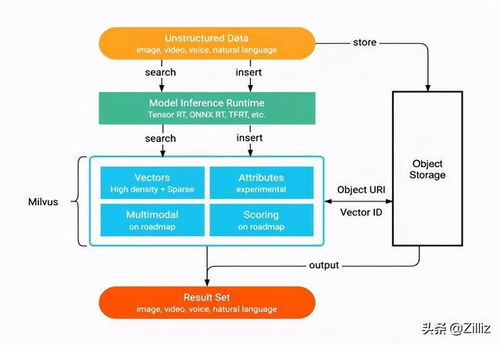
成功的存儲實踐始于對業務場景的深刻理解。團隊應首先明確工作負載特性(是訓練密集型還是推理密集型),制定清晰的SLA(服務等級協議)。建議采用“數據湖倉一體”架構,統一管理原始數據、特征庫和模型資產,并配備強大的元數據管理系統。
存儲系統將更加智能化,能夠主動預測數據訪問模式并進行預置或遷移。存儲與計算的協同設計也將更加緊密,如計算存儲分離架構的進一步演進,以及存算一體等新型硬件技術的探索,有望從根本上重塑大模型的基礎設施范式。
大模型存儲絕非簡單的硬件堆砌,而是一個需要持續權衡性能、成本與多云復雜性的系統工程。構建一個高效、經濟、靈活且穩健的存儲底座,是釋放大模型全部潛力的必要前提。